
Projects
A1: Algorithms for Multi-objective Optimization Problems in Geodesy
PI and members: Heiko Röglin (University of Bonn), Sarah Sturm
Summary
In geodesy, multi-objective optimization problems are ubiquitous.
An example from project C1 are clustering and aggregation problems in cartography
where one has to cluster areas and aggregate them into larger regions and there are
multiple objectives one wants to optimize. Another example from project C2 comes
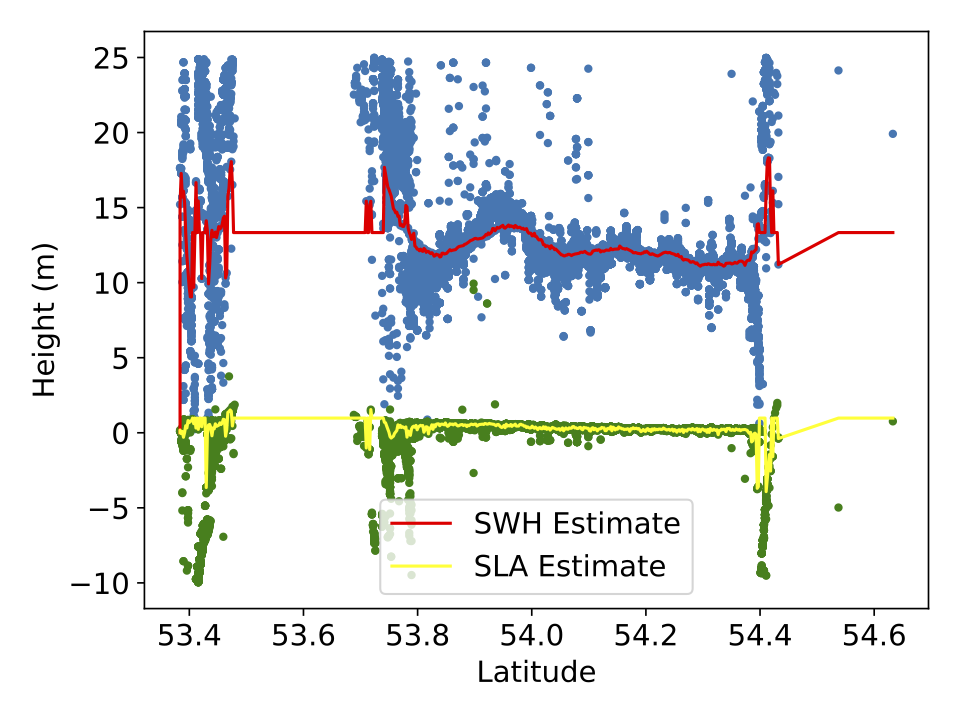
from satellite radar altimetry of the sea surface where one wants to estimate both
the sea surface height (SSH) and the significant wave height (SWH) from satellite data,
which leads to a multi-objective shortest path problem.
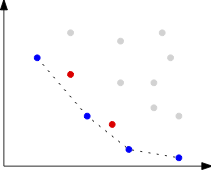
A common approach to handle multi-objective optimization problems is to combine the
different criteria into a single objective by taking a weighted sum.
This weighting is often artificial and can result in a loss of information.
We will make use of the full potential of multi-objective optimization and study
in particular the set of Pareto-optimal solutions.
We will develop algorithms
for efficiently computing or approximating this set for the problems mentioned above
and other problems motivated by applications from geodesy. We will collaborate with
A2, B1, B2, and C1 on multi-objective clustering and aggregation problems,
with C1 and C2 on multi-objective triangulations, and with B2, C1, and C2 on
multi-objective shortest path problems. Our algorithms will be analyzed theoretically
but also implemented and tested in cooperation with projects C1 and C2 as well as B2.
This will lead to both improved solutions in practice and novel theoretical results.
A2: Approximation Algorithms for Clustering, Aggregation and Simplification under Side Constraints
PI: Melanie Schmidt (University of Düsseldorf)
Summary
This project focuses on the aspect of side constraints in the context of clustering,
aggregation and simplification problems from geodesy and on the question to what extend
it is possible to efficiently find approximative solutions for constrained problems.
Side constraints occur naturally both in the process of digitally designing maps and
in sea surface representation.
Clustering problems as studied in combinatorial optimization are often NP-hard even
without side constraints, i.e., it is most likely not possible to solve them optimally
in polynomial time. Typical solutions for this are to use ILP formulations and speed up
(exponential-time) algorithms in practice, or to design application specific heuristics.
An alternative are approximation algorithms: These aim to find solutions with a provable
worst-case guarantee in polynomial time. For classical clustering algorithms, there exists
a large variety of approximation algorithms.
Although clustering problems arising in geodesy are often related to those clustering problems
that are studied extensively in the theory and algorithms community, they differ in
important aspects: a) They involve many side constraints and b) the input objects can be
complex objects like polygons, graphs or time series. In this project, we aim to advance
the state-of-the-art for approximation problems for clustering of complex geometric objects
under side constraints.
A3: Scalability of Geometric Clustering Algorithms
PI and members: Christian Sohler (University of Cologne), Jan Hoeckendorff
Summary
Due to vast amounts of sea surface height data and very large geographical data sets,
there is an increasing need for highly scalable clustering methods that deal with
geometric data representations. Therefore, main objective of this project within the RU
is to develop and analyze new algorithmic concepts to improve scalability of geometric
clustering algorithms with provable guarantees.
In order to achieve this goal, we will develop new concepts of dimension reduction for
geometrically represented objects such as polygonal curves and corresponding distance
measures such as the Fr\'echet distance. For center-based clustering methods with complex
geometric centers such as subspace clustering, we will develop new sampling approaches to
reduce the number of input points and for clustering of geometric objects we will develop
new data reduction methods that combine simplification, dimension reduction and sampling
methods to improve scalability of algorithms.
We will implement and engineer the most promising approaches and provide them as new tools
to projects C1 and C2 to study problems in the context of map aggregation andsea level height
analysis, representation and reconstruction.
B1: Efficient Representation of Geometric Similarity
PI: Anne Driemel (University of Bonn)
Summary
Algorithms in geodesy often need to determine if two geometric objects
are similar or dissimilar. Depending on the specific application, the algorithm
needs to be provided with a definition of this dissimilarity, which is usually done
in the form of a mathematical distance measure. Broadly speaking, the aim of this
bridge project is to study the mathematical structure and complexity of several
distance measures relevant to this RU on two levels: (i) on the level of the distance
between two individual objects via a study of the complexity of the distance computation,
and (ii) on the level of the entire metric space via a study of the VC dimension of the
corresponding set system of metric balls.
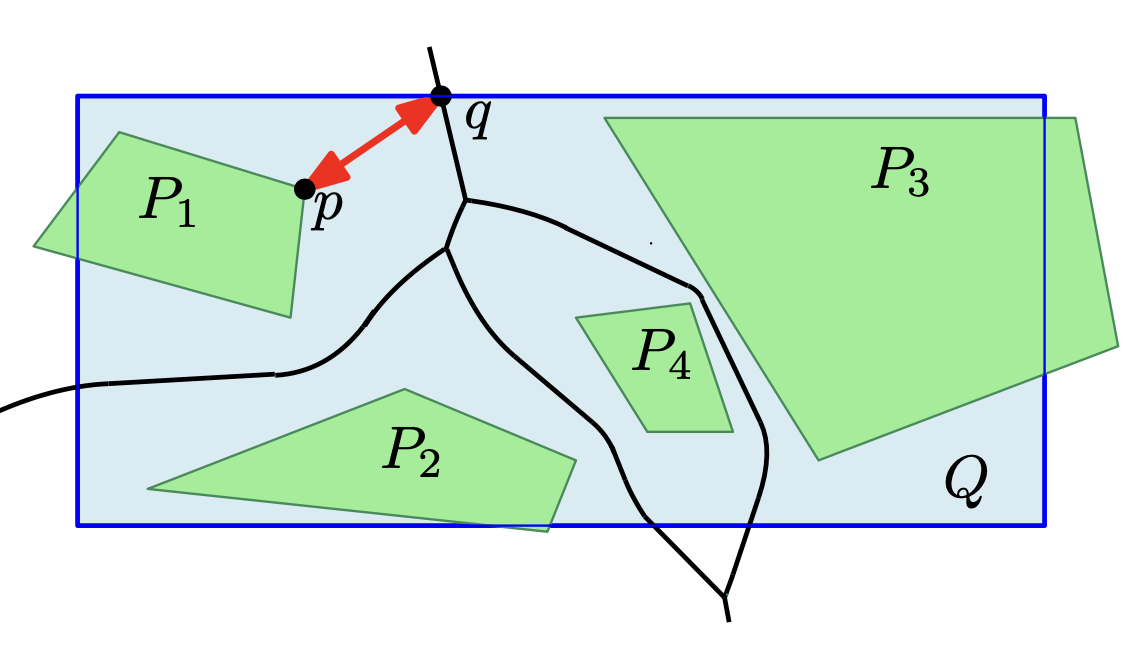
We will explore adaptations of different
geometric distance measures, such as the Fréchet distance and the Hausdorff distance,
which are known to capture continuous geometries well. The distance measures are developed
in close collaboration with the geodesy experts of projects C1 and C2 and algorithms
experts of A1, A2, A3, and B2 to ensure (i) suitabilty to the application and (ii)
efficient computability. In this way, the project is closely integrated into collaborations
across the entire RU.
The ultimate goal of the project is to study new algorithmic methods
for clustering, aggregation and simplification involving polygonal curves and polygonal regions.
The new methods should be applicable to cartographic generalization, as well as clustering of
ocean remote sensing data. In both cases, the algorithm should find a compact representation
of geometric objects which maximizes the similarity to the measured data points under an
appropriate definition of geometric similarity. To achieve the goal of wide applicability,
we study the clustering and aggregation problems that arise within this RU within the framework
of geometric set cover formulations.
B2: Algorithm Engineering for Geometric Graphs
PI and members: Petra Mutzel (University of Bonn), Philip Mayer, Jonas Charfreitag
Summary
Within our RU graphs appear directly as cartographic maps or indirectly as their
geometric dual graphs, as shortcut graphs or as triangulations.
Within this project, we will consider these structures as geometric graphs, i.e. graphs
embedded on the plane (or on a surface). These graphs are often sparse, even planar,
and thus allow for more efficient graph algorithms than general graphs.
We will develop algorithmic engineering approaches for practically solving discrete optimization
problems on geometric graphs related to the clustering, aggregation, and simplification problems
that occur within our RU. An important goal is to speed up and to improve the quality of
combinatorial as well as integer-linear-programming approaches for discrete (multi-objective)
optimization problems on geometric graphs. This will be achieved by carefully taking the graph
topology and the (geometric) structure of the given input data into account, sometimes in
combination with learning approaches. For some of these problems, new similarity measures for
geometric graphs, which we will develop jointly with B1, will play an important role.
Another important ingredient are carefully engineered data structures to support queries about
graphs and interactive maps.
As a bridge project, jointly with B1, we will make sure that the theoretical concepts and algorithms
suggested in projects A1, A2, and A3 will find a suitable realization in the geodesy projects C1
and C2. Our work program is closely interlinked with all the other subprojects.
C1: Simultaneous Simplification and Aggregation for Interactive Maps
PI: Jan-Henrik Haunert (University of Bonn), Alexander Naumann
Summary
To use a geographic data set in a spatial analysis or for a map, one often needs to coarsen
its granularity. In geographic information science and cartography, this task is termed
generalization. Project C1 will contribute to automated generalization by developing algorithms
for detecting groups of objects in a geographic data set and computing a single representative
and simplified object for each group.
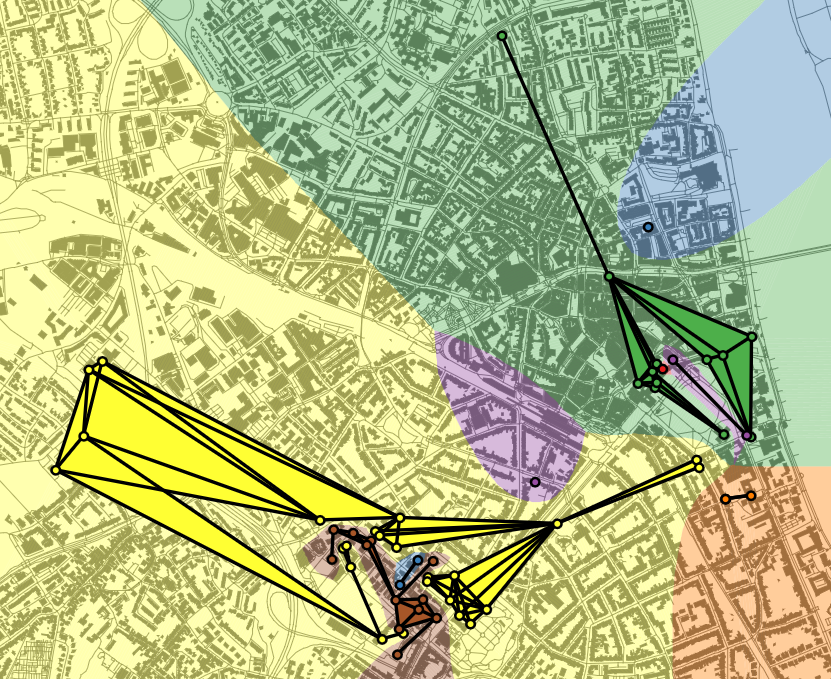
As two concrete use cases we will study (i) the delineation of regions of human activity based
on geo-tagged social-media data and (ii) the derivation of polygons corresponding to built-up
areas, settlements, and larger urban agglomerations from footprints of individual buildings.
In both cases we aim at interactive maps that allow their users to zoom through different scales
and to change the map's point of reference in time or its interval of reference in time.
For example, by dragging a time slider, a user can change the map's point of reference in time
to obtain an animation of urban growth over multiple years.
We will develop an approach that treats the detection of groups of objects, the aggregation of
each group to a polygon, and the simplification of polygons as a single task.
Our central hypothesis is that such an integrated approach yields substantially better solutions
than the currently dominating approach of first aggregating and then simplifying.
The development will follow an algorithm engineering process including the modelling of problems,
the design of efficient algorithms, mathematical analyses, and experiments.
C2: Understanding Global Patterns of Sea Level Rise and Ocean Heat Redistribution
PI and members: Jürgen Kusche (University of Bonn), Bernd Uebbing
Summary
Project C2 will address questions that are fundamental to our understanding of climate change:
What are theregional rates of sea level rise? How is regional sea level rise related to changes
in sea level extremes andto changes in sea state? To what extent do satellite observations of
the sea surface fit to modelling of ocean heat change (OHC)? Which patterns of heat redistribution
can be derived from satellite observations?
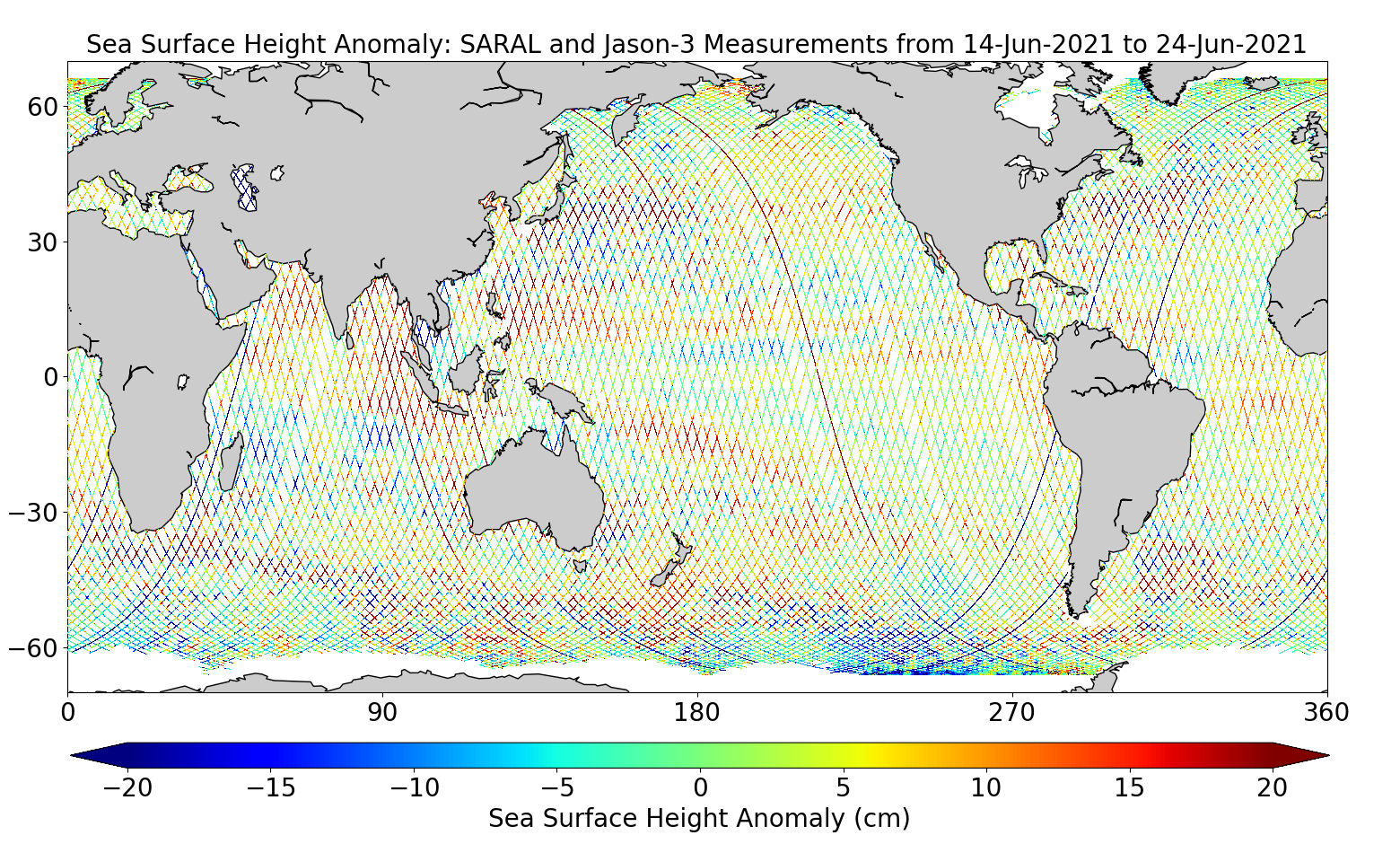
Wewill explore the synergy in the RU to better exploit the vast archive of satellite data and
ocean modelling. New and efficient methods for geometric representation and clustering data
will be tailored to the problem (AI methods have been introduced in ocean remote sensing before,
but these were mostly transferredfrom image analysis and often did not properly account for the
geometrical nature of the problems).
Thus,within this RU, we decided to address four particular problems with novel AI-based methods:
(1) Consistent analysis of radar echoes for sea surface height (SSH) and
significant wave height (SWH), (2) Combining and analysing SSH variability,
(3) Reconstructing multi-decadal SSH with sparse data, and (4) inverting radar observations
of SSH into OHC. These problems follow the analysis chain in sea level research, but they can
be addressed independently.